In any large systems there has to be an explicit notion of architecture. The basic objects, and processes of the system have to be explicitly identified. One of the major problems within almost any reserach field is that the researchers do not have experience in large system buildinbg and often spend more time on the reserach than on system management leading to a very unweildly system which is difficult to modify and maintain.
In the MITalk book, allen87 a basic pipeline architecture is used. Basically each module reads in some structured information form the preceeding module and outputs a new structure for the succeeding module. This model has the disadvantage that anything that is needed by a later module must be preoperly outputed by each intervening module. This is especially difficult when the modules are different (e.g. Unix) processes as in the Bell Labs 1972 system.
An alternative architecture is a blackboard architecture where a global is accessible to all modules which may add and modify as these require. The exact line between such architectures is fuzzy
Orthogonal to the issue of pipeline versus blackboard there is the important aspect of how the respentation of an utterance itself should be structure. Choosing the right structure is very important. As it defines what can and cannot be done easily within the archtecture.
@cindex{string model} The first such utterance structure is the string model. Here a string of synbols is incrementally modified through each modules. For example if we start with a string of tokens.
We started on Feb 25.
The first expansion modules would replace all tokens with words to give a string
We started on february twenty fifth .
Other modules would replace words with phones, then phoens with phones+durations etc. In this model we have effectively unstructured data sitting in a simple list at each stage.
@cindex{multi-level data structures} Another problem that is not catered for in the simplest string model is that information about previosu levels is lost at each stage. Thus multi-level data structures can be used so that each new module adds new levels, without removing old ones.
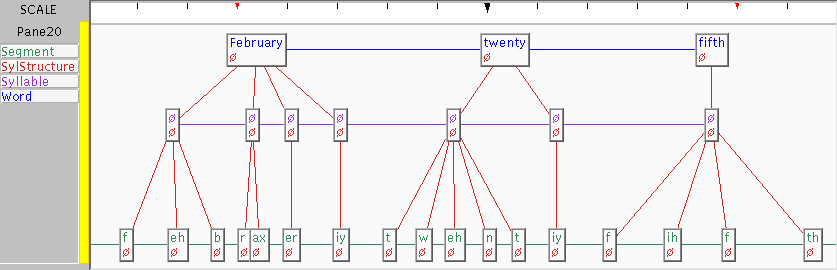
This again can be done in multiple ways. One way is to build a table where bounaries denote times in the eventual synthesized utterance. Thus we have something like
| Feb | 25 | | february | twenty | fifth | | 1 | 0 | 0 | 0 | 1 | 0 | 1 | | f | eh | b | r | ax | er | iy | t | w | eh | n | t | iy | f | ih | f | th |
Thus giving layers for tokens, words, syllables and phones.
Unfortunately this nice heirarchical structure doesn't always match what you want to do. Intonation accents and boundaries can best be done orthogonal to syllables. Diphones also cross over boundaries. A second rpoblem is that although we now have multi-levels each level is still a simple list. IF we wish to add syntactic parsing, or prosodic phrasing tree represenations would be best. This ouwl require further additions to this structure. The third aspect to consider is traversal of this tructure to find related information. Thus what is the mechanism to find the first phone in a word. Although all such "problems" can be dealt with in this model some are stretching the structure in ways that it was not originally designed to be used.
It is not unusual that the basic structure set up to hold complex objects in a system, although carefully designed at the start, becomes a burden such that new ideas and concepts become so difficult to implement within that structure that such enhancements are not considered.
The fundamental object used in Festival system is the utterance. Each module in the system is given an utterance which it will manipulate in some way and then pass on to the next module. Given Festival started as a new system recently it is able to benefit from the limitations found in previous systems.
An utterance consists a set of items which are related through a set of relations. An item may be in one or more relations. Each relation consists of a list or tree of items.
Items are used to represent objects like words or segments, but also sometimes more abstract objects like a node in a syntax tree. An item has a number of features associated with it. Each feature has a feature name and feature value, the name is a simple striing while the value may be a string, integer or float, (or also any other complex object).
Relations are used to link items together is useful
ways. Such as in a list of words, or a syntax tree or the
syllable structure. Individual items may be in multiple relations,
for example a word will be in the Word relation as well as
being the SylStructure relation as the root of a tree describing
its syllable structure.
For example a basic utterance can contain a number or relations.
Here we show a Word, Syllable and Segment
list relations with a tree-structured SylStructure relation
overlayed.
We call this structure a heterogeneous relation graph (or HRG). A more detailed dicussions of the benefits and its relationship to other structures is given in taylor98b.
There is no fixed set of relations and new ones can easily be added, at run-time, or existsing ones ignored. However in the standard English voice a set of standard relations are used and wil be refered to though this course.
Token relation. They may also appear in the Syntax
relation (as leafs) if the parser is used. They will also be leafs
of the Phrase relation.
Word's within those phrases.
Word relation.
Word, Syllable and
Segment relations. Each Word is the root of a tree
whose immediate daughters are its syllables and their daughters in
turn as its segments.
SylStructure relation. In that relation its parent will be the
word it is in and its daughters will be the segments that are in it.
Syllables are also in the Intonation relation giving links to
their related intonation events.
SylStructure relation. These may also be in the
Target relation linking them to F0 target points.
Intonation relation as leafs on that
relation. Thus their parent in the Intonation relation is the
syllable these events are attached to.
Intonation are Syllables and their daughters
are IntEvents.
wave whose value
is the generated waveform.
To access information in items in an utterance a simple feature mechanism has been implemented. Each item holds features named by a string, feature values may be strings, integers or floats. For example here is how to access an utterance through features in Scheme. Suppose we create an utterance as follows
(set! utt1 (SayText "The book is on the table"))
We can extract the first word from this
(set! firstword (utt.relation.first utt1 'Word))
We can find the part of speech of this word by accessing
its pos feature.
(item.feat firstword "pos")
As well as basic features other complex feature names allow access to other parts of the utterance. For example to find the first segment in this word
(item.feat firstword "R:SylStructure.daughter1.daughter1.name")
Dot separated tokens in the feature name may refer to other items
related to the given item either within the current relation or
through others. A number of direction operators
are defined n (next), p (previous), daughter1
(first daughter), daughter2 (second daughter), daughtern
(last daughter), parent, first (most previous),
last (most next). Also the token immediately following
the prefix R: is treated as a relation name and current
relation is switched to it. For example
(item.feat firstword "n.pos")
Accesses the next word's part of speech.
(item.feat firstword "n.R:SylStructure.daughter1.stress")
Accesses the next words, first syllable's stress value.
If a feature name doesn't point to a valid place (e.g. there is
no next item. "0" is returned.
Features allow a uniform method for accessing the utterance allowing many simple models, such as CART trees, linear regression etc. to take parameters in a clean way. For example a decision tree to assign accents on stressed syllables in content words or on unstressed syllables in single-syllable content words may be represented as
((R:SylStructure.parent.gpos is content) ((stress is 1) ((Accented)) ((position_type is single) ((Accented)) ((NONE)))) ((NONE))))
where R:SylStructure.parent.gpos, stress, and
position_type are all features.
Each utterance also has a type. Synthesis is defined in terms of the type of an utterance.
A module is a process that can be applied to an utterance.
For example the following creates an utterance of type Text
(Utterance Text "hello")
When synthesized, using the utt.synth function the utterance's type,
Text, defines which modules get run on the input.
(defUttType Text (Initialize utt) (Text utt) (Token utt) (POS utt) (Phrasify utt) (Word utt) (Intonation utt) (Duration utt) (Int_Targets utt) (Wave_Synth utt))
Or when segments are explicitly included in the input none of the higher level analysis need be done
(Utterance Segment ((h 0.058) (@ 0.039)
(l 0.069) (ou 0.219)))
(defUttType Segment
(Initialize utt)
(Wave_Synth utt))
Choices between different modules of the same type (e.g. different
duration modules) are done through the Parameter mechanism.
For example if you want to select Klatt duration rules
use
(Parameter.set 'Duration_Method 'Klatt)
Or if you wish to select average duration then use
(Parameter.set 'Duration_Method 'Averages)
To find out the appropriate parameter names and values consult the relevant chapters in the manual.
(set! total_ns (+ 1 total_ns)) (format t "Total number of nouns %d\n" total_ns)
Tokens UttType for list of extra
modules to call. You want to look at the Segment relation
(if (string-equals (item.feat seg "ph_vc") "+")
(set! total_vs (+ 1 total_vs))
)
Text UttType for list of
modules to call.
The following functions are useful:
(utt.relationnames utt) (utt.relation.items utt 'Segment)The following actually works for trees and lists
(utt.relation_tree utt 'Segment)
(set! seg4 (nth 4 (utt.relation.items utt 'Segment)))
(item.features seg4)
Go to the first, previous, next, last section, table of contents.