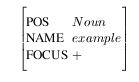| Edinburgh Speech Tools Library |  | ||
|---|---|---|---|---|
| Prev | Next | |||
EST offers a comprehensive intgerated system for handling and storing linguistic information of all types. This system is based on the Hetrogeneous Relation Graph formalism. There is a basic hierarchy of 5 main classes in this part of the library:
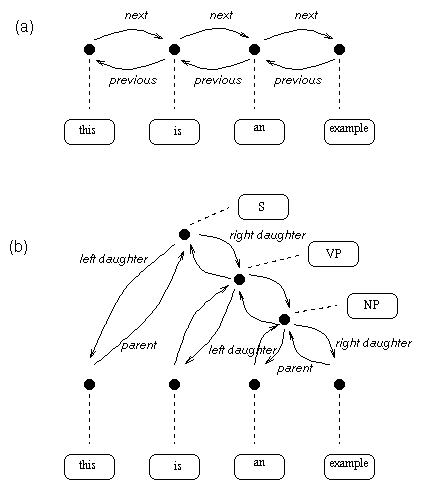
Relations store ordered collections of linguistic items. The most common basic types are the list and the tree. Figure 6-1 shows two examples of relations. Figure 6-1a shows a word relation of the sentence ``this is an example''. This relation is a simple linear list. Figure 6-1b shows a syntax tree of the same sentence. Both figures are comprised of three components: items, nodes and arcs. The items contain the linguistic information (in this case the name of the word or syntactic category), whereas the nodes and arcs define the relationship between the items.
In the list case, the arcs occur in complimentary pairs named next and previous, allowing forward and backwards traversal. In the tree case the arcs occur in complimentary pairs named parent and daughter1, daughter2 etc. All arcs in a HRG occur in named complimentary pairs: by convention next and previous are used for lists, and parent, daughter etc for trees.
Formally, relations can be seen as either directed graphs, where arcs occur in complimentary named pairs, or as acyclic graphs, in which an arc has two complimentary names. A node may have any number of arcs. The names of the arcs in the outgoing direction must all be unique, whereas the names of the arcs in the incoming direction do not have to be unique. (For example in the tree, a node can have two incoming nodes named ``parent'' for traversal from its daughters, but the names of the nodes to those daughters must be called something like ``left daughter'' and ``right daughter''.)
In these simple examples, the use of nodes and items is clearly redundant as all nodes and items have a one-to-one relationship. However, this is often not the case in that although a node can be linked to only one item, an item can be linked to many nodes, so long as each is in a different relation. Figure 6-2 shows a structure representing the combination of Figure 6-1a and Figure 6-1b. The syntax and word relations are the same, but the nodes of the word list and the terminal nodes of the syntax tree point to the same items. This a the key feature of the HRG system. Of course it would be possible to keep the information separate as in figure Figure 6-1, but this is redundant because these items really do represent the same word. As will be seen below items can be very complex structures and it would be wasteful to duplicate the information. More importantly, information in items is often changed in the synthesis process and there is a chance of the syntax and word items becoming inconsistent. A list of named backwards links to nodes is kept in each item, so that given an item, any node in any relation linked to that item can be easily found.
In a simple examples such as this, it is possible to imagine a situation where the word relation is defined to be a traversal of the terminal nodes in the syntax relation. However, in the general case, more complex intersecting relations are often required and such simple approaches will fail.
Items are attribute value lists (AVL) which contain linguistic information. All ``atomic'' linguistic entities such as words, syllables and phones are represented by items.
In the simple sense, attributes are named linguistic properties such as part-of-speech, place of articulation, duration etc, and values are strings, enumerated sets (that is, a value from a fixed list of possibilities), floating point numbers and integers. Equation 6-1 is a typical word item:
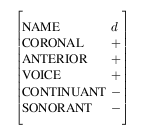
and example Equation 6-2 is a typical phoneme item:Items are not directly typed, in that there is nothing in the AVL itself to say if it is a phoneme, syllable or word. Rather, typing comes from the fact that it is linked to a node in a relation. Items in the word relation are words, items in the syntax relation are syntactic constituents and items in both have both types.
Values need not be atomic types. Often it is unattractive to store all the information in an item as a single flat attribute-value list. For example, in a traditional binary phonological feature system such as SPE \cite{spe} descriptions of segments are typically given as
However, it can be useful to provide a named hierarchy on the features: This is useful in specifying the consequences of traditional phonological rules such as syllable-final nasal assimilation. In some situations, the place of articulation of a nasal is assimilated to the place of articulation of the following stop (e.g. ``ten'' + ``bags'' -> ``tembags''). If the feature bundle mechanism is used, an additional mechanism (indicated by the reference [1]) allows the value of an item to be a AVL in a different item. In the above example the fact that the place of articulation is the same for the nasal and stop is shown by using a reference for the place of articulation of the nasal, which refers to the place of articulation of the stop. The use of the feature bundle to represent place of articulation allows this operation to be done with a single reference rather than by a two separate references to CORONAL and ANTERIOR.Often feature bundles are simply used as a tidying mechanism. For instance, it is usually not necessary to access phonological feature and timing information at the same time, so a neater mechanism for storing this on a phone would be:
The last important feature mechanism is function values, which is when a function rather than an atomic value is the value of an attribute. Discussion of function values is given in the section on timing as they are particularly relevant to that issue. stuff