 |
Edinburgh Speech Tools
2.4-release
|


|
|
Edinburgh Speech Tools
2.4-release
|
|
Test n-gram language model
ngram_test [input file0] [input file1] ... [-w ifile] [-S ifile] [-raw_stats ] [-brief ] [-f ] [-input_format string] [-prev_tag string] [-prev_prev_tag string] [-last_tag string] [-default_tags ]
ngram_test is for testing ngram models generated from ngram_build.
How do we test an ngram model?:
ngram_test will compute the entropy (or perplexity, see below) of some test data, given an ngram model. The entropy gives a measure of how likely the ngram model is to have generated the test data. Entropy is defined (for a sliding-window type ngram) as:
![\[H = -\frac{1}{Q} \sum_{i=1}^{Q} log P(w_i | w_{i-1}, w_{i-2},... w_{i-N+1}) \]](form_20.png)
where 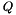 is the number of words of test data and
is the number of words of test data and 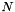 is the order of the ngram model. Perplexity is a more intuitive mease, defined as:
is the order of the ngram model. Perplexity is a more intuitive mease, defined as:
![\[B = 2^H \]](form_23.png)
The perplexity of an ngram model with vocabulary size V will be between 1 and V. Low perplexity indicates a more predictable language, and in speech recognition, a models with low perplexity on test data (i.e. data NOT used to estimate the model in the first place) typically give better accuracy recognition than models with higher perplexity (this is not guaranteed, however).
ngram_test works with non-sliding-window type models when the input format is ngram_per_line.
Input data format: The data input format options are the same as ngram_build, as is the treatment of sentence start/end using special tags.
Note: To get meaningful entropy/perplexity figures, it is recommended that you use the same data input format in both ngram_build and ngram_test, and the treatment of sentence start/end should be the same.
 1.8.3.1
1.8.3.1