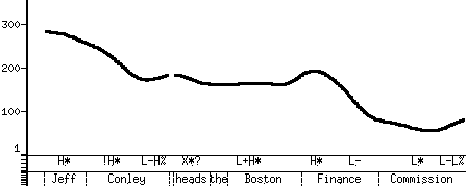
This is the second stage in text to speech. We now have our words, what we need to produce is something to say. For this we will require segments (phonemes), durations for them and a tune (F0).
Although this can be in the most naive way, the quality of the speech, how natural, how understandable, how acceptable it is depends largely on the appropriateness of the phonetic and prosodic output. Prosody in language is used to add variation for emphasis, constrast and overall easy of unstanding and passing the message to the listener. The degrees of variation in prosody depend a lot on the language being spoken. Some things are lexical and cannot be changed without changing the words being spoken. For example lexical stress in English is part of the definition of a word, if you change the position of the stress you can change the word (e.g. from "pro'ject" (noun) to "proje'ct" (verb)). In other languages, such Chinese, tones play a part in lexical indentification thus changing (though not removing) the possible uses of F0 in utternaces.
Bad prosody makes utterances very difficult to near impossible to understand and so it is important for a speech synthesis system to generate appropriate prosody.
The simplest way to find the pronunciation of a word is to look it up in a word list or lexicon. This should give the syllabic structure, lexical stress and pronunciation in some phoneme set. For some languages (and for some words in some languages) this mapping may be trivial and there could exist a well-define mapping from the orthography to the pronunciation, Latin and Spanish are examples of languages where lexicons for pronunciation are mostly redundant. However in English this is not so trivial.
Some languages require analysis of the word into sub-parts or
morphs removing their various modifications (usually
prefixes and suffixes). For example in English we might
only store the pronunciation of move in our lexicon and
derive from it the pronunciation of moved, moving,
mover, movers, etc. This a trade-off between
lexicon size and amount of effort required to analyze a word.
Languages such as German with significant compounding may require
some form of morphological decomposition. Others with significant
amount of agglutinative morphology (like Finnish and Turkish) cannot
realistically be done without morphological analysis. Various
semitic language like Arabic with vowel harmony require quite
novel methods to analyze. See ritchie92 for more details
than you need.
The size and necessity of a lexicon is language dependent, but it is almost always convenient to have at least a small list for various acronyms and names etc. In fact although quite large lexicons (10,000s to 100,000s of words) are readily available for English, German and French, it is almost always the case that some words are missing from them and a localized lexicon of specific task specific words are required. This typically includes proper names, login names, etc.
Of course no matter how hard you try you are not going to be able to list every word. New ones are created often, certainly new names come into focus as world events happen. It is of course not acceptable for a speech synthesizer to fail to pronounce something so a fall back position that can guarantee pronunciation is important. Letter to sound rules can help with this. Often words can be pronounced reasonably from letter to sound rules. If the word isn't in the lexicon (i.e. this implies its not common), a guess at pronunciation might work, after all that's what humans need to do when they see a word for the first time. In some languages (e.g. Spanish) letter to sound rules can do the whole job for almost all words in the language.
In Festival a lexicon consists of three parts (all optional)
Multiple lexicons are supported at once as different lexicons may be required even for the same language, e.g. for dialectal differences. The phones produced by a lexicon should be suitable for the waveform synthesis method that is to be used (though Festival does supports phoneme mapping if really desired).
It is necessary for all words to be assigned a pronunciation but it is practically impossible to list all words in a lexicon. The solution to this is to offer a mechanism that assigns a pronunciation to words not found in the lexicon or agenda. For some languages where the orthography closes maps to pronunciation (e.g. Spanish) almost all pronunciation can be done by letter to sound rules.
The rule supported in Festival are fairly standard. The basic form of rule is
( LEFTCONTEXT [ ITEMS ] RIGHTCONTEXT = NEWITEMS )
For example
( # [ c h ] C = k ) ( # [ c h ] = ch )
The # denotes beginning of word and the C is defined to
denote all consonants. The above two rules which are applied in order,
meaning that a word like christmas will be pronounced with a
k which a word starting with ch but not followed by a
consonant will be pronounced ch (e.g. choice.)
Rules are quite difficult to write but are quite powerful. Work has been done on learning them automatically both by neural net and statistical processes but those results have typically not been used in real synthesis systems. When building synthesizers for many languages and dialects it is necessary to be able to provide letter to sound rule sets quickly and efficiently so being about to automatically build rules from examples (e.g. a lexicon) is desirable.
black98b provides a basic trainable letter to sound rules system within the Festival framework. The idea is that from a reasonably sized lexicon a letter to sound system can be automatically generated. At repsent the process requires a little hand seeding but fairly minimal and unskilled. The results from applying this technique to English (UK and US), German and French are good and it seems very unlikely their quality godd be beaten by hand written rules without an awful lot of work (i.e. years of skilled labor).
The technique falls into two phases. First built alignments between letters and phones from the lexicon and secondaly build (CART) models to predict phones form letter contexts.
There are typically less phones that letters in the pronunciation of many langauges. Thus there is not a one to one mapping of letter t phones in a typical lexical pronunciation. In order for a machine learner technique to build reasonable prediction models we must first align the letter to phones, inserting epsilon where there is no mapping. For example
Letters: c h e c k e d Phones: ch _ eh _ k _ t
Obviosuly there are a number of possibilities for alignment, some are in some way better than others. What is necessary though is to find these alignments fully automatically.
We provide two methods for this, one fully automatic and one requiring hand seeding. In the full automatic case first scatter eplisons in all possible ways to cause the letter and phoens to align. The we collect stats for the P(Letter|Phone) and select the best to generate a new set of stats. This iterated a number of times until it settles (typically 5 or 6 times). This is an example of the EM (expectation maximisation algorithm).
The alterantive method that may (or may not) give better results is to
hand specify which letters can be rendered as which phones. This is
fairly easy to do. For example, letter c goes to phones k
ch s sh, letter w goes to w v f, etc. Typically all
letter can at some time go to eplison, consonants go to some small
number of phones and letter vowels got to some larer number of phone
vowels. Once the table mapping is created, similary to the epsilon
scatter above, we find all valid alignments and find the probabilities
of letter given phone. Then we score all the alignments and take the
best.
Typically (in both cases) the alignments are good but some set are very bad. This very bad alignment set, which can be detected automatically due to their low alignment score, are exactly the words whose pronunciations don't match their letters. For example
| dept @tab d ih p aa r t m ah n t |
| lieutenant @tab l eh f t eh n ax n t |
| CMU @tab s iy eh m y uw |
Other such examples are foreign words. As these words are in some sense non-standard these can validly be removed from the set of examples we use to build the phone prediction models.
A second compliation is that some letters more resonable rendered as more than one phone. For example
x as k-s @tab in box |
l as ax-l @tab in able |
e as y-uw @tab in askew |
Currently these dual phones are simple added to the phone list and treated like any other phone, except they are split into the two individual phones after prediction.
CART trees are build for each letter in the alphabet (twenty six plus any accented characters in the language), using a context of three letters before an three letters after. Thus we collect features sets like
# # # c h e c --> ch c h e c k e d --> _
Using this technique we get the following results.
| OALD (UK English) @tab 95.80% @tab 74.56% |
| CMUDICT (US English) @tab 91.99% @tab 57.80% |
| BRULEX (French) @tab 99.00% @tab 93.03% |
| DE-CELEX (German) @tab 98.79% @tab 89.38% |
The differences here reflect both the complexity of the language and the complexity of the particular lexicon itself. Thus the apparently much poorer result for US English (CMUDICT) over UK English (Oxford Advanced Learner's Dictionary) is due not only to OALD being done more carefully from a single source, but also the fact that CMUDICT contains many more proper names than OALD which are harder to get right. Thus although OALD appears easier on this held out data (every tenth entry from the lexicon), it is actually doing an easier task and hence fails more often of real unknown data, which more often contains proper names.
This brings into a number of notions of measurement that will be touched upon through this course. First how well does the test set reflect the data we actually wish to apply the model too. And secondly does the correctness measure actually mean anything. In the first case we note that different training/test sets even from the same dataset can give varying results. So much so that in LTS models its pretty difficult to compare any two LTS ruls sets except when they've been applied ot he same train/test set.
The second aspect of measurement is the question of how well does the notion of correct match what the system is actually going to do for real. In order to get a better idea of that we tested the models on actual unknown words from a corpus 39,923 words in the Wall Street Journal (from the Penn Treebank marcus93). Of this set 1,775 (4.6%) were not in OALD. Of those 1,360 were names, 351 were unknown words, 57 were American spelling (OALD is a UK English lexicon) and 7 were misspelling.
After testing various models we found that the best models for the held out test set from the lexicon we not the the best set for genuinely unknown words. BAsically the lexicon optimised models were over trained for that test set, so we relaxed the stop criteria for the CART trees and got a better result on the 1,775 unknown words. The best results give 70.65% word correct. In this test we judged correct to be what a human listener judges asa correct. Sometimes even though the prediction is wrong with respect to the lexical entry in a test set the result is actually acceptable as a pronunciation.
This also highlights how a test set may be good to begin with after some time and a number of passes and corrections to ones training algorithm any test set will be become tainted and you need a new test set. It is normal to have a development test which is used during development of an algorithm then keep out a real test set that only get used once the algorithm is developed. Of course as development happens in cycles the real test set will effectively become the development set and hence you'll need another new test set.
Another aspect to letter to sound rules that we've glossed over is the prediction of lexical stress. In English lexical stress is important in getting the pronunciation right and therefore must be part of the LTS process. Originally we had a separate pass after phone prediction that assigned lexical strees but following bosch98 we tried to combine the lexical stress prediction with the phone prediction. Thus we effectively doubles the number of phone vowels by adding stressed and unstressed versions of them. This of course makes letter to phone prediction harder as there are more phones, but overall it actually gives better results as it more correctly predicts stress values.
Note that a word's printed form does not always uniquely identify its pronunciation. For example, there are two pronunciations of the word live. Although by no means common, homographs (words written the same but pronounced differently) occur in most languages. The most common way to distinguish them is by part of speech--though that is still not enough for some pessimal cases (see discussion above about homograph disambiguation).
For example wind as a verb is pronounced w ai n d while as
a noun it is w i n d. But this is not completely true as
w i n d can be both a noun and a verb as can w ai n d.
Rather than give up in despair we find that if we could label every word
with its part of speech we can reduce the number of homograph errors
significantly.
In Festival we have implemented a standard statistical part of speech tagger (DeRose88) which gives results around 97% correct tags for major classes. Comparing this against a test set of 113,000 words and a lexicon identifying homographs we find we make about 154 errors in pronunciation of homographs. There are significantly more spelling errors in these course notes than that, so the results are probably good enough.
But Festival still makes pronunciation errors. Pronunciation errors are very noticeable and memorable so they interfere with our understanding of the speech. Typical errors that still occur are
It is necessary to split utterance into prosodic phrases. When people speak they phrase their speech into appropriate phrase based on the content, how they wish to chunk things, and also how large their lungs are. Prosodic phrases probabaly have an upper bound, definitely less than 30 seconds and probably less than 15 seconds.
When looking break utterances into phrases in a text to speech system we have a number of options. Obviously breaks at punctuation are a reasonably place to start, but its not quite as simple as that.
bachenko90 describe a rule driven approach making use of punctuation, part of speech and importantly syntactic structure. This produces reasonably results but requires syntactic parsing to work, which is resource expensive and prone to error. One important finding is highlighted in this work. Phrasing tends to be balanced, that is we prefer to keep chunks roughly the same size, so factor like number words in phrase make a difference. Although prosodic phrasing is influenced by syntactic phrasing is can cross tranditionaly syntatic boundaries. For example a verb may bind with a subject or an object and will typical do so to the shorted or the two (to keep balance).
(the boy saw) (the girl in the park) (the boy in the park) (saw the girl)
hirschberg94 uses CART trees and get excellent results (95% correct) for a simple corpus using features such as word, part of speech, distance from previous and to next punctuation.
ostendorf94 offer a stochastic method, still using CART trees but do many more experiments looking at the advantages and disadvantages of different features. The also describe a hierarchical model to find the optimal prosodic labelling of different levels of breaks in utterances.
Festival supports two major methods, one by rule and the other using a statistical model based on part of speech and phrase break context black97a.
The rule system uses a decision tree, which may be trained from data or hand written. A simple example included in `lib/phrase.scm', is
(set! simple_phrase_cart_tree
'
((R:Token.parent.punc in ("?" "." ":"))
((BB))
((R:Token.parent.punc in ("'" "\"" "," ";"))
((B))
((n.name is 0) ;; end of utterance
((BB))
((NB))))))
This is applied to each word in an utterance. The models may specify
any of three values (currently these names are effectively fixed due to
their use in later models). NB stands for no break, B for
small break, BB for large break. This model is often reasonable
for simple TTS, but for long stretches with no punctuation it does not
work well.
This model may take decision trees trained using CART so allows implementation of the technique discussed in hirschberg94. Experiments have been done like this but the results have never been as good as their's.
Following the work of sanders95 we have a more complex model which compares favourably with most other phrase break prediction methods.
Most methods try to find the likelihood of a break after each word but don't take into the account the other breaks that have already been predicted. This can often predict breaks at places where there is a much more reasonably place close by. For example consider the following two sentences
He wanted to go for a drive in. He wanted to go for a drive in the country.
Although breaks between nouns and prepositions are probable a break should not occur between "drive" and "in" in the first example, but is reasonable in the second.
The more elaborate model supported by Festival finds the optimal breaks in an utterance, based on the probability of a break after each word (based on its part of speech context), and the probability of a break based on what the previous breaks are. This can be implemented using standard Viterbi decoding. This model requires
See black97a for details of experiments using this technique.
We again hit the problem of what is correct when it comes to phrasing. Almots nay phrasing can in some context be correct but it seems some phrasing for utterance sis more natural than others. When you comparing the output of a phrasing algorithm against some database where natural phrasing is marked some of the error will reflect just simply the freedom of choice in placing phrase boundaries while other parts of the error are unacceptable errors. Unfortuantely these different types of error can't easily be identified.
ostendorf94 uses a test set of multiple speakers saying the same data. They consider a prediction correct if there is any speaker who spoke that utterance with all the same phrase breaks. This attempts to capture some the random selection of possible phrasing for an utterance.
Note also how in different contexts different type of phrasing are appropriate. In conversational speech we are inclined to add many more break and use them more as a mechanism for information. In reading new text however we are much more likely to use a more standard phrasing. Thus when a synthesis system uses a phrase break algorithm trained from news speech it probabaly isn't appropriate for conversational speech. Thus the ability to change phrase break algorithm when the speaking style changes in important.
There are probably more theories of intonation that there are people working in the field. Traditionally speech synthesizers have had no intonation models (just a monotone) or very poor ones. But today the models are becoming quite sophisticated such that much of the intonation tunes produced are often very plausible.
Intonation prediction can be split into two tasks
This must be split into two tasks as it is necessary for duration prediction to have information about accent placement, but F0 prediction cannot take place until actual durations are known. Vowel reduction is another example of something which should come between the two parts of tune realization.
The two sections may be done by rule or trained, Festival supports various methods to do this.
hirschberg92 gives detailed (complex) rules to predict where accents go in utterances. black95a gives a comparison of Hirschberg's system and CART trees. The basic first approximation for accent prediction, in English, is to accent all stressed syllables in content words. This basically over assigns accents and is most noticeably wrong in compound nouns. But even this simple heuristic can be around 80% correct.
Accent type is a slightly different problem. The ToBI (silverman92) intonation theory states that there are only a small number of distinct accents in English, about 6. Therefore, we need to then choose between these 6 accents types. Although there seems to be some linguistic difference in the use of each accent its difficult to fully identify it. Statistically trained methods (again CART) produce reasonable but not stunning results.
Some theories, like ToBI make distinctions between accents and boundary tones. Tones are the intonation events that occur at the end (or start) of prosodic phrases. The classic examples are final rises (sometimes used in questions) and falls (often used in declaratives).
Festival allows accent placement by decision tree. A rather complex example trained from American news speech is in `FESTIVALDIR/lib/tobi.scm' which shows the sort of tree you need to get reasonable results.
A much more simple example is just to have accents on stressed syllables in content words (and single-syllable content words with no stress). A decision tree to do this is as follows
(set! simple_accent_cart_tree
'
((R:SylStructure.parent.gpos is content)
((stress is 1)
((Accented))
((position_type is single)
((Accented))
((NONE))))
((NONE))))
Again there are various theories for F0 generation, each with various advantages and disadvantages. This is of course language dependent but a number of methods have been relatively successfully over multiple languages.
fujisaki83 builds an F0 contour from parameters per prosodic phrase and has good results for simple declarative (Japanese) sentences. taylor94b has a more general system which can automatically label contours with parameters and generate contours from these parameters for a wide range of intonation tunes (work is progressing to integrate this into Festival dusterhoff97a). The ToBI system says little about generation of the F0 contour from their higher level labels but black96 gives a comparison of two techniques. ToBI as yet has no auto-labeller (though there are people working on it).
Note that an auto-labelling method is desirable because it can generate data from which we can train new models.
This task of generating a contour from accents is actually much better defined than generating the accent placement or their types.
Festival supports a number of methods which allow generation of target F0 points. These target points are later interpolated to form an F0 contour. Many theories make strong claims about the form of interpolation.
The simplest model adds a fixed declining line. This is useful when intonation is be ignored in order test other parts of the synthesis process.
The General Intonation method allows a Lisp function to be written which specify a list of target points for each syllable. This is powerful enough to implement many simple and quite powerful theories.
The following function returns three target points for accented syllables given a simple hat pattern for accents syllables.
(define (targ_func1 utt syl)
"(targ_func1 UTT ITEM)
Returns a list of targets for the given syllable."
(let ((start (item.feat syl "syllable_start"))
(end (item.feat syl "syllable_end")))
(if (not (eq? 0 (length (item.relation.daughters syl "Intonation")))
(list
(list start 110)
(list (/ (+ start end) 2.0) 140)
(list end 100)))))
Of course this is too simple. Declination, change in relative heights, speaker parameterization are all really required. Besides what height and width should accents be?
Based on work in jilka96 there is an implementation of a ToBI-by-rule system using the above general intonation method in `lib/tobi_f0.scm'.
A different method for implementing ToBI is also implemented in Festival and described in black96. In this model, linear regression is used to predict three target values for every syllable using features based on accent type, position in phrase, distance from neighbouring accents etc. The results appear better (both by listening and measuring) than the rule approach. But of course in this case we need data to train from which we do not always have.
This section gives a basic description of a number of different computational intonation theories with their relative advantages and disadvantages.
ToBI (Tones and Break Indices) silverman92 is a intonational labeling standard for speech databases that in some way is based on Janet Pierrehumbert's thesis pierrehumbert80.
The labelling scheme consists of:
H*, !H, L*,
L*+H and L+H*.
H- and L-
L-L%, L-H%, H-L% and H-H%
HiF0 marker for each intonational phrase
A ToBI labeling for an utterance consists of a number of tiers. The accent and boundary tone tier, the break level tier and a comment level tier.
As is basically stands ToBI is not designed as computational theory that generation allows of an F0 contour from a labelling, or generation of labels from an F0, but it has been used as such. anderson84 offer a rule based method for generating F0 contours from a basic ToBI-like labelling. Their basic structure is to define a set of basic heights and widths for each accent type. A baseline which declines over time is defined and the accents are placed with respect to this baseline. All values in their initial implementation were hand specified.
Another implementation, again basically by rule, is jilka96. An implemenation of this rule system is given in the festival distribition in `festival/lib/tobi_rules.scm'.
The standard voices in festival also use a basic ToBI framework. Accents and boundary types are predicted by a CART tree, but the F0 generation method is a statistically trained method as described (and contrasted with anderson84) in black96. In this case three F0 values are predicted for each syllable, at the start, mid vowel and end. They are predicted using linear regression based on a number of features including ToBI accent type, phrase position, syllable position with contexts. Although a three point prediction system cannot capture all the variability in natural intonation, by experiment it has been used to be sufficient to produce reasonable F0 contours.
The Tilt Intonation Theory taylor00a, in some sense takes a bottom up approach. Its intention is to build a parameterization of the F0 contour, that is abstract enough to be predictable in a text to speech system. A Tilt labelling of an utterance consists of a set of accent and boundary labels (identified with syllables). Each accents has 4 continous parameters which characterize the accents shape position etc. These parameters are:
Also each intonation phrase has a startF0 value.
It has been shown that a good representation of a natural F0 contour can be made automatically from the raw signal (though it is better of the accents and boundaries are hand labelled). dusterhoff97a further shows how that parameterization can be predicted from text.
The Fujisaki model fujisaki83, is again a bottom up data-driven model. It was originally developed for Japanese, though also has a German model moebius96. In the Fujisaki Model intonational phrases are represented by an phrase command and an accent command, and number of accent commadns may exist in each phrase. Hear a command" consists of an amplitude and a position. The model is a critically damped impluse modul where the F0 decays over time based on the enerygy inserted by phrase and accent commands. This model is argued to be physiologically based.
Moehler moehler98 offers a model that uses both the nothings of data-driven as in Tilt and the Fujisaki model, but also the advantages of a phonology model like ToBI. He paramterizes the F0 in a way not-dissimilar to Tilt, but importantly then clusters differnt types of intonation contours by vector quanitization. Thus he has say 8 different types of accent that are data derived. Experiments in syrdal98a show this method to be better than Tilt and the black96 model.
Ross ross96 uses a dynamical model to represent the F0 and has good results on the Boston University FM Radio corpus.
A final method worth mentioning which offer much promise is to use the selection natural contours from aprorpriate speech examples rather than predict a new one. Using techniques very similar to what is becoming common in waveform (segmental) unit selection malfrere98.
Although tests have often been made to show how a theory may be better than some other thoery, actually the results of such tests should be not taken as absolute. In all cases the people doing the tests spend more time on implementing and tuning a particular theory than its competitors. I'm not writing this because syrdal98a shows other work to be better than work done previously by me, I'm as guilty of this in black96 where I implemented both techniques. However although broad ordering of theories is probabaly correct depending too much on the F0 RSM error and corelation is almost certainly too naive a measure for true qualitative measures of a theory's correctness.
We have simply stated that intonation invovles modelling the F0 (underlying tune) of an utetrance. In this section we'll be more specific about what we means by F0 and how one can find it in speech.
The F0 is the basic tune in speech for mails it usually ranges between about 90Hz and 120Hz and about 140Hz to 280Hz in females. In general an F0 starts higher at the begining on a sentence and gets lower of time, reflect the depletion in the air rate as we speak, though it is possible to make it rise over time. In English, accents will appear at important words in the sentence, though their shape, amplitutde, duration and exact position will vary.
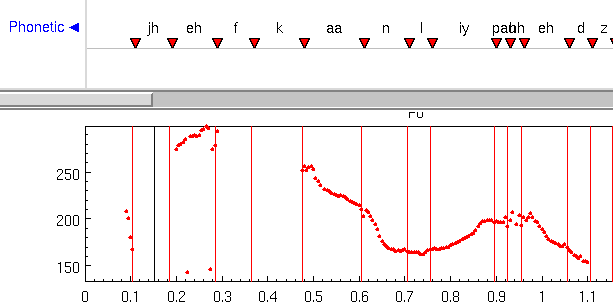
A typical F0 will look like
The F0 is in fact not as smooth as this. First, there are only pitch periods during voiced speech, second certain segments (particularly obstruents such as stops), can locally affect the pitch so that the underlying natrual paitch may actaully look like the following rather than the above.
Note that there is no F0 during the /f k/ as these are unvoiced. Also not the somehwta variable F0 valuse around the /hh/ of "heads" which although we may state is unvoiced actually as pitch periods near it.
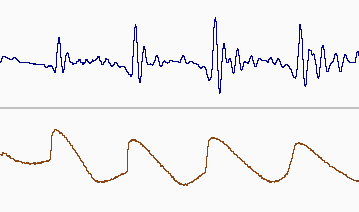
When modelling F0 it is useful to have a clea prepresentation of it. As extraction methods of F0 from raw wave signals are prone to error we also, where exact F0 representation is important, we can also record the electrical activity in the glottis and predict F0 from that. We do this with an electro-glottograph (EGG) some called a larygnograph though first name is easier to say. The device consists of two small electrodes that are strapped to the throat while recording. The signal, when listened to sounds like a muffled buzz (cf. Kenny from South Park). The following shows a waveform signal with the corresponding EGG signal for the nonsense word /t aa t aa t aa/.
If we zoom in we can see the EGG signal (on the bottom) is much cleaner that the top one. Though it should be noted this is a particularly clean signal.
Extracting F0 from waveforms is not as difficult as speech recognition but is still a non-trival problem (hess83). Most algorithm require (or at least work much better with) knowledge of the range of the speaker. Though frequency doubling and halving is still a common type of error. One of the standard tools in pitch detection algorithms is autocorelation.
There are two basic uses of F0 extraction, first to get the whole contour. In this case smoothing is almost certainly required to filling unvoiced sections (by interpolation) and to smooth out segmental perturbations (so-called micro-prosody). In this case what is required is a track of values at fixed intervals (say 10ms) giving the approximate F0 values throughout the utterance.
The second use of F0 extraction is in signal process which is dicussed in detail later. In this case each pitch period is indetified exactly. Many signal processing techniques that can modify pitch and duration independantly work on the pitch periods of a signal. It is easier to get an estimate of the pitch over a section of waveform than to reliably get the pitch period properly identified hence F0 modelling can (and is) often done from pitch contours extracted from a waveform but it is harder to do signal processing cleanly without an EGG signal, evn though it is desirable not to rely on the extra piece of informatiom.
In all of the current synthesis techniques we will talk about, explicit segmental durations are necessary for synthesis. Again many techniques have been tried, many of which are supported by Festival.
The easiest method is to use a fixed size for all phones. For example 100 milliseconds. The next simplest model assigns the average duration for that phone (from some training data). This actually produces reasonable results. However you can quickly hear that phones in an average only model sound clipped the start and end of phrases. Phrase final lengthening is probably the most important next step.
The Klatt duration rules are a standard in speech synthesis. Based on a large number of experiments modifications from a base duration of all the phones are describe by a set of 11 rules, allen87. These modify the basic duration by a factor based on information such as position in position in clause, syllable position in word, syllable type, etc. The results sound reasonable though a little synthetic. These rules are one of the fundamental features that people subconsciously identify when recognizing synthetic speech.
Others have tried to look at predicting durations based on syllable timings rather than the segmental effect directly campbell91. They've had some success and is an area actively studied in duration prediction.
In Festival we support fixed, average and duration modified by rule. The Klatt rules are explicitly implemented. Our best duration modules are those trained from database of natural speech using the sorts of features used in the Klatt rules but deriving the factors by statistical methods.
A simple duration decision tree predicts a factor to modify the average duration of a segment. This tree causes clause initial and final lengthening as well as taking into account stress.
(set! spanish_dur_tree
'
((R:SylStructure.parent.R:Syllable.p.syl_break > 1 ) ;; clause initial
((R:SylStructure.parent.stress is 1)
((1.5))
((1.2)))
((R:SylStructure.parent.syl_break > 1) ;; clause final
((R:SylStructure.parent.stress is 1)
((2.0))
((1.5)))
((R:SylStructure.parent.stress is 1)
((1.2))
((1.0))))))
There are some segmental effects which cannot be determined for words in isolation. They only appear when the pronunciations are concatenated. May of these co-articulatory effects are ignored in synthesis which often leads to what appears to be over-precise articulation.
One effect that can however be easily dealt with is vowel reduction. The effect often happens in non-important function words. Although this can be trained from data we can specify mappings of full vowels to schwas is specific contexts.
Another form of reduction is word contractions, as is "it is" to "it's". This is very common in speech and makes a synthesizer sound more natural.
Festival supports a general method for post-lexical rules. These may be specified on a per-voice basis. Although some phenomena occur across dialects some are dialect specific.
For example in British English, post-vocalic "r" is deleted unless it is followed by a vowel. This can't be determined in isolated words for word final r's so this is done as a post-lexical rule. We apply the following simple CART to each segment in the segment relation after lexical look up to decide if the "r" has to be deleted or not.
(defvar postlex_mrpa_r_cart_tree '((name is r)
((n.ph_vc is -)
((delete))
((nil)))
((nil)))
Linguistic/Prosodic processing is the translation of words to segments with durations and an F0 contour.
Specifically we have identified the following modules
Although all of these can implemented by simpel rules, they can be trained (to some degree) from data. In is generally agreed that data driven models are better though often in specificase hand written rules will win. Note it is much easier to tweak a rule to cater for a particaulr phenomena that tweak a statistically model to better highlight a rare phenomena in a traing set.
A important aspect to measuring correctness of linguistic and prosodic models is to realise the distinction between existing mathematical measures and human perception. For example in measuring a duration model we can find the root mean squared error and correlation of a prediction model with respect to a test set. Those figures can then be used to judge how good a duration model is. But we are assuming that these are corelated with human perception which although maybe broadly true is almost certainly an over-simplication. Mathematical models which properly corelate with human perception are necessary for proper prosodic models but at present are not easily available. It is often said that synthesis should use more human listening tests in evaluation but note that developing preoper human evalation tests is in itself difficult and values received from them are also prone to error as they still are indirect measures of human perception.
(set! int_accent_cart_tree
'
((R:SylStructure.parent.gpos is content)
((stress is 1)
((Accented))
((position_type is single)
((Accented))
((NONE))))
((NONE))))
And you'll need to write a function that generates the F0 targets,
something like
(define (targ_func1 utt syl)
"(targ_func1 UTT ITEM)
Returns a list of targets for the given syllable."
(let ((start (item.feat syl "syllable_start"))
(end (item.feat syl "syllable_end")))
(cond
((string-matches (item.feat syl "R:Intonation.daughter1.name") "Accented")
(list
(list start 110)
(list (/ (+ start end) 2.0) 140)
(list end 100)))
(
;; End of utterance as question
;; target for mid point and high end pont
)
( ;; End of utterance but not question
;; target for mid point and low end pont
))))
The condition (equal? nil (item.next syl)) will
be true for the last syllable in the utterance and
(string-matches (item.feat syl "R:SylStructure.parent.R:Word.last.R:Token.parent.punc") "\\?")
will be true if there is a question mark at the end of the utterance.
You also need to set up these functions as the intonation method
(Parameter.set 'Int_Method 'General)
(set! int_general_params
(list
(list 'targ_func targ_func1)))
Phrasify module to the function find-pos.
In the loop that extract information about each word in an utterance
you must add a new feature pbreak to give the value of
break after that word. The function itself (with the printfp)
print out each word and a space (the variable space contains
a space that prints without quotes round it) but only call
terpri when the pbreak value is B (or twice
when the value is BB).
Go to the first, previous, next, last section, table of contents.